Video Temporal Grounding (VTG)
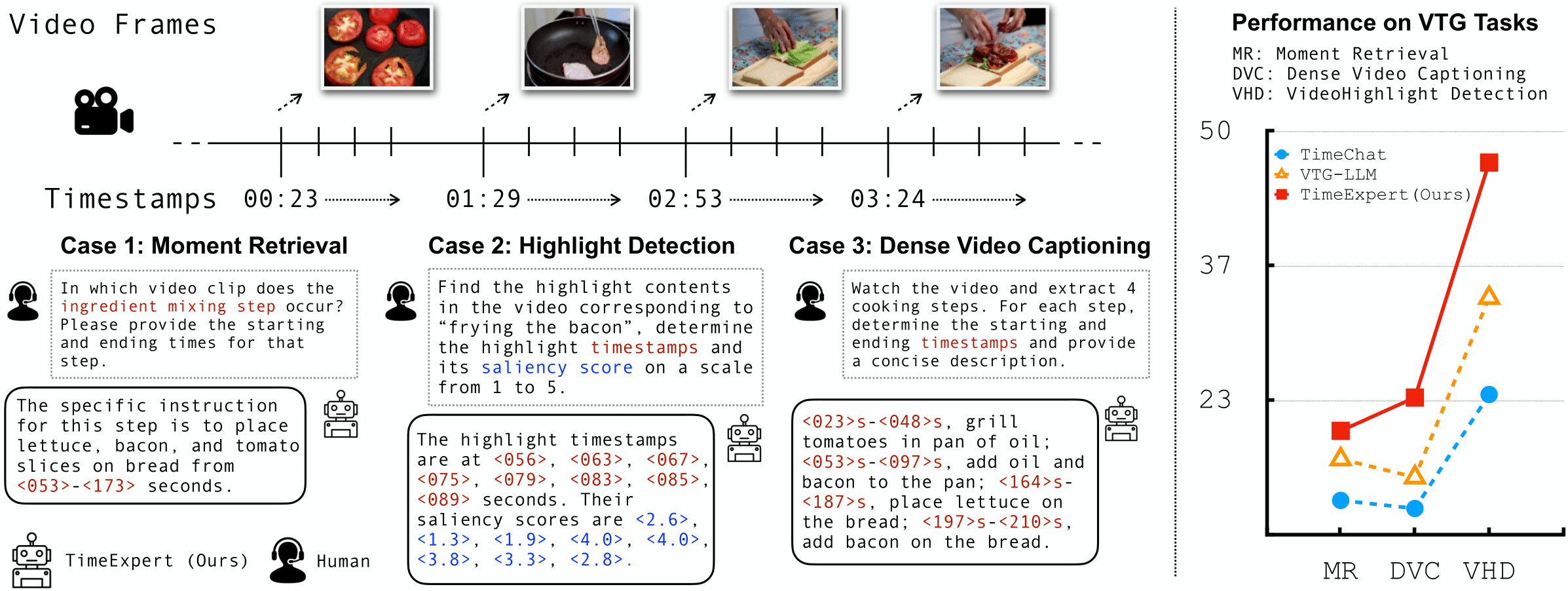
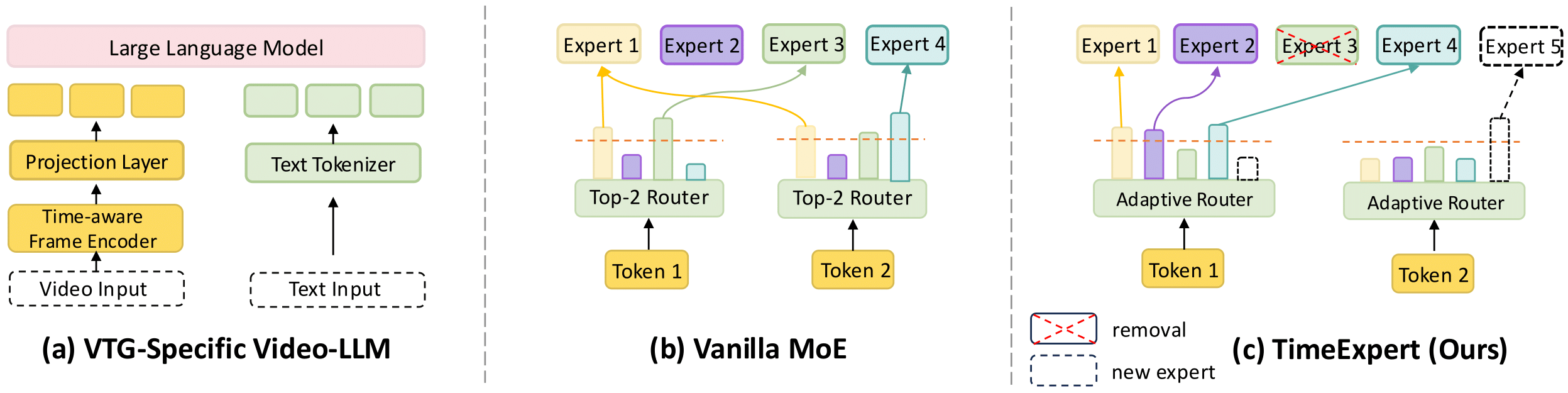
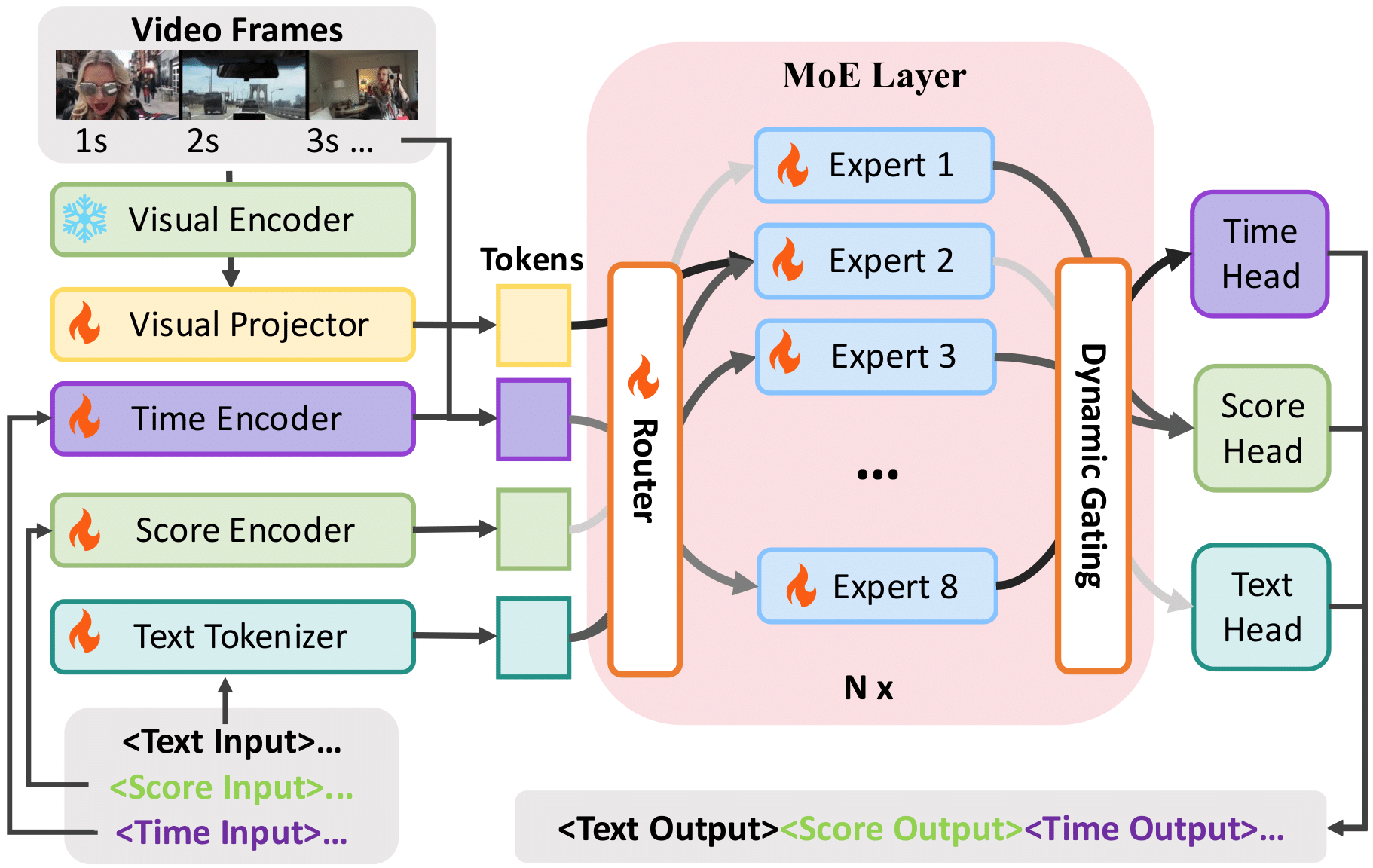
Left: Video Temporal Grounding (VTG) is a fine‑grained video understanding task that aims to accurately locate content along with event timestamps based on natural language queries. In this work, we mainly consider three major types of VTG tasks: (1) Moment Retrieval (MR), (2) Video Highlight Detection (VHD), and (3) Dense Video Captioning (DVC). The outputs of VTG often contain textual captions, timestamps, and saliency scores. Right: Unlike existing methods (e.g., TimeChat) that employ a single static model, motivated by expert specialization on different task tokens, we propose TimeExpert, an expert‑guided Video LLM with dynamic token routing. Through task‑aware expert allocation, TimeExpert demonstrates substantial improvements over state‑of‑the‑art Video‑LLMs on several VTG benchmarks. For example, here we visualize zero‑shot F1 score for DVC on the YouCook2 dataset, R@1IoU=0.7 for MR on the Charades‑STA dataset, and HIT@1 for VHD on the QVHighlights dataset. More results and analysis are in the experimental section.